Empregando técnicas de Data Science e Machine Learning, tentei estimar o IDH por bairro na cidade de São Paulo a partir dos dados de IDH disponíveis por bairro e dos geodados de locais fornecidos pela API do FourSquare

São Paulo é uma cidade com 22 milhões de habitantes e também a cidade mais rica do Brasil, com um PIB de cerca de 130 mil milhões de dólares, sendo uma das maiores e mais ricas cidades do planeta. É a 10ª maior cidade do mundo em termos económicos (Wikipédia).
No entanto, tal como o Brasil, São Paulo também aparece nos rankings mais elevados de desigualdade. Este país é o vigésimo mais desigual do planeta (Wikipédia) e São Paulo foi a 9ª cidade mais desigual entre as maiores cidades do mundo em 2016 (Euromonitor).
O IDH (Índice de Desenvolvimento Humano) já demonstra uma enorme diferença entre regiões e bairros de São Paulo. No entanto, como são médias que agregam grandes áreas, é possível que o cenário de desigualdade fosse ainda pior se a medida do IDH fosse mais granular.
Para granular o IDH e obter um mapa mais detalhado da desigualdade, tomei os bairros e suas coordenadas geográficas como uma unidade menor para estimar o IDH, obtendo mais pontos de medida dentro de cada bairro.
Como estava a tentar construir um mapa mais detalhado da desigualdade, foram utilizadas diferentes fontes de dados públicas, como a Wikipédia, o Kaggle e outras disponíveis online.
IDH por distritos na cidade de São Paulo
Índice de Desenvolvimento Humano (IDH) por distritos na cidade de São Paulo está disponível em Wikipédia. O IDH varia de zero (menos desenvolvido) a um (mais desenvolvido). Esse conjunto de dados foi utilizado para treinar um modelo de Aprendizado de Máquina para estimar o IDH de bairros de São Paulo, considerando suas características em termos de disponibilidade de espaços.
Conjunto de dados de geolocalização Olist
Em Kaggle, está disponível um conjunto de dados públicos de E-Commerce brasileiro por Olist, incluindo um Conjunto de dados de geolocalização, com coordenadas de pedidos de comércio eletrónico. Este conjunto de dados foi utilizado para encontrar geolocalizações relevantes para representar os bairros de São Paulo.
Ficheiros GeoJSON de distritos e bairros de São Paulo
Em Carto.com, podemos encontrar vários ficheiros de estruturas de dados geográficos (GeoJSON). Distritos de São Paulo GeoJSON (por ArteFolha) foi utilizado para definir as geolocalizações dentro de cada distrito. Da mesma forma, Bairros de São Paulo GeoJSON (por Andre Monteiro) foi utilizado considerando os limites dos bairros de São Paulo.
Endpoint de exploração de locais da API do FourSquare
Para comparação entre distritos e bairros, o Recomendações de locais por FourSquare foi utilizado para obter dados de geolocalizações relevantes utilizadas para representar áreas em São Paulo.
A fim de obter os dados necessários, processá-los e usá-los para construir um mapa mais detalhado da desigualdade da cidade de São Paulo, os seguintes procedimentos foram tomados:
a. Definir geolocalizações relevantes para a coleta de dados
Considerando as latitudes e longitudes brasileiras no Olist Geolocation Dataset, apenas as geolocalizações da cidade de São Paulo foram mantidas. Para isso, foi utilizado o GeoJSON Bairros de São Paulo para filtrá-lo.
Em seguida, as latitudes e longitudes foram arredondadas para três casas decimais (cerca de 111 metros de resolução), a fim de otimizar o processamento e também para permitir identificar as geolocalizações relevantes em cada bairro.
Utilizando o GeoJSON dos Bairros de São Paulo, as restantes geolocalizações foram classificadas por bairros, sendo depois seleccionadas as mais frequentes em cada bairro para o representar.

b. Recolha dados de locais a partir da API do FourSquare
O ponto de extremidade Venues Explore da API do FourSquare foi utilizado para recolher dados de locais próximos das geolocalizações seleccionadas. Após os pedidos da API, foi criado um perfil das categorias de locais de cada geolocalização.
c. Transforme e verifique os dados agrupados por freguesias e bairros
Depois de recolher e transformar os dados disponíveis na API do FourSquare, os bairros e as freguesias foram agrupados utilizando dados de categorias de locais por geolocalização utilizando a função método KMeans de Biblioteca Scikit-learn.
Este é um gráfico dos bairros de São Paulo agrupados por perfil de categorias de locais:

Este é um gráfico dos bairros de São Paulo agrupados por categorias de locais perfil:

Aparentemente, comparando os gráficos, os dados fornecidos pelo FourSquare eram consistentes e poderiam fornecer aspectos relevantes dos bairros de São Paulo, especialmente quando comparamos a área central com outras.
Além disso, os dados dos bairros indicam a existência de diferenças relevantes dentro dos bairros.
e. Estimar o IDH usando dados dos locais
A fim de estimar o Índice de Desenvolvimento Humano (IDH) para cada bairro da cidade de São Paulo, os dados do IDH por distritos foram usados para treinar um modelo de Aprendizado de Máquina, especificamente um modelo XGboost Regressor, usando o Interface Scikit-Learn Wrapper para XGBoost .
Inicialmente, o modelo foi treinado com apenas 80% dos dados de IDH por distrito e testado contra os 20% restantes, fornecendo estimativas de IDH com 0,037393 como raiz do erro quadrático médio (RMSE). No entanto, utilizando a validação cruzada, o RMSE foi de 0,044548.
As características mais importantes considerando o modelo treinado são mostradas abaixo:

Diante disso, um novo modelo foi novamente treinado a partir dos dados de IDH por bairros, agora para tentar estimar o IDH para os bairros de São Paulo, considerando suas características em termos de geodistribuição de locais.
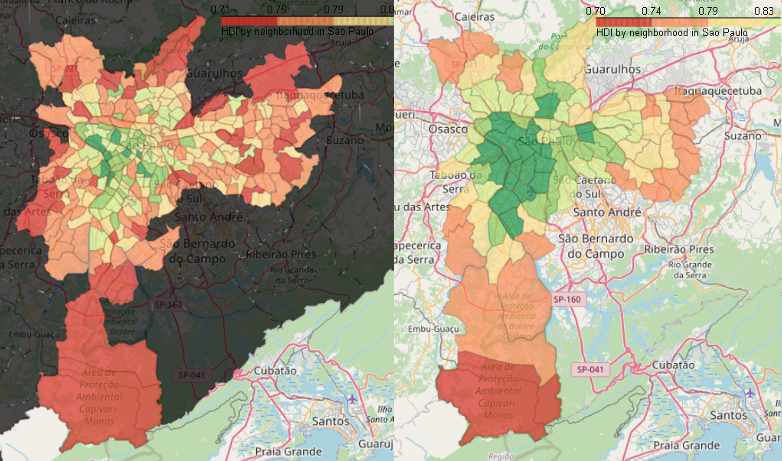
Como resultado, obteve-se uma visão detalhada da desigualdade dentro dos distritos de São Paulo, não apenas entre eles, mas também entre os bairros, conforme o gráfico abaixo:

Os bairros com menor IDH estão em vermelho, enquanto os de maior IDH são mostrados em verde (os amarelos têm IDH médio). As áreas em preto correspondem à ausência de IDH estimado (a maioria delas se refere a outros municípios da Região Metropolitana de São Paulo).
O mapa acima pode ser comparado com o mapa original do IDH por distritos na cidade de São Paulo:

A partir do primeiro mapa, é possível avaliar diferenças relevantes entre bairros de um mesmo distrito. Esse tipo de visualização não era possível utilizando apenas o segundo mapa.
No mapa obtido, alguns bairros de São Paulo não foram plotados devido ao fato de que o IDH estimado não foi calculado. Isso pode ter diferentes razões, como a falta de informações para determinados bairros no Olist Geolocation Dataset ou falha na seleção e processamento ou classificação de geolocalizações em bairros e distritos.
Além disso, a seleção de mais do que uma geolocalização por bairro, ou mesmo a divisão dos bairros em áreas mais pequenas (utilizando prefixos de códigos postais, por exemplo), pode levar a uma visão mais detalhada das diferenças entre áreas mais próximas.
O Jupyter Notebook com o código utilizado neste projeto está disponível aqui, incluindo mapas interactivos.
Espero que tenha gostado deste post e tenciono continuar com este projeto em breve, melhorando-o, lançando uma versão portuguesa de um artigo mais completo, adicionando uma API para expor o IDH estimado por geocoordenadas ou por nomes de bairros.
Para já, está convidado a ver mais coisas no meu blogue ou em rafael.digital! Obrigado!